
mmap, munmap - map or unmap files or devices into memory
mmap(2) is a system call that creates a mapping between the virtual address space of your process and a file descriptor. You can then access memory in that virtual address space as if it were memory, and blocks of the file will be efficiently paged into and out of memory transparently in such a way that is sympathetic with the page size, filesystem block size and (hopefully) the underlying hardware. Here it is:
void *mmap(void *addr, size_t length, int prot, int flags,
int fd, off_t offset);
It's a brilliantly simple API. The kernel handles reads and writes for you in the background without necessarily buffering everything in precious memory, dealing with batching and persistence along the way. It's such a successful abstraction that many databases use for persistence, because there are distinct advantages to letting the kernel deal with these directly. As the sqlite page on mmap explains, mmapped pages share memory with the kernel's page cache, which can reduce memory use and copying from user to kernel space.
But what happens when the kernel doesn't do the right thing? In fact, what does the kernel even do? The answer to this question depends on what kernel you're using; in fact, it really depends: mmap behavior is firmly in the territory where not all unixes think alike.
The general behavior of the mm is to run page flushing threads on an interval and flush dirty pages matching certain criteria. Over the years, the linux kernel has done this with kflushd, bdflush, pdflush, and most recently a set of kernel flusher threads which are difficult to find documentation on.
Vestiges of these flusher techniques persist both in internet documentation (tuning redhat 3 for oracle!) and on modern systems themselves; even though bdflush has done nothing since linux 2.4, the manpages and interfaces are still there in sys/kdaemon.h on modern linuxes. There are still pdflush-specific procfs nodes like sys/vm/nr_pdflush_threads which do nothing and are scheduled for removal.
The linux kernel has a number of vm sysctls which allow you to tune the flusher thread behavior:
vm.dirty_bytesandvm.dirty_background_bytesare memory usage thresholds in bytes; after this much memory is occupied by dirty pages, the flusher activates.vm.dirty_ratioandvm.dirty_background_ratioset a maximum ratio of dirty pages to "active" ones, defined as MemFree + Cached - Mappedvm.dirty_writeback_centisecssets the interval on which the kernel flush threads will wake up in hundredths of a second, eg.500is 5 seconds.vm.dirty_expire_centisecsis, well..
Ostensibly, vm.dirty_expire_centisecs defines a threshold in number of seconds whereby data older than it will be written out the next time a flusher thread wakes. The mechanics if this in practice might not be as one would expect. As Jan Kara explains on the lkml:
When the first page is dirtied in an inode, the current time is recorded in the inode. When this time gets older than dirty_expire_centisecs, all dirty pages in the inode are written.
What are the implications of this?
If you were expecting slow but steady writes dirtying a large number of pages to be flushed gradually after the expiry period, then you're going to have a bad time. Setting dirty_expire_centisecs to a high value and dirtying all pages gradually is a sure way to have to flush the entire file at once later on.
The Road to Hell
Given the above, the worst write loads for mmap would be systems where most or all of the pages are dirtied continuously. Such systems are not that uncommon. Consider a system with the following behavior:
- files contain data representing N minute chunks
- the "current" N-minute chunk is written to randomly w/ high throughput
- non "current" files rarely get writes and reads generally hit the same small sets of pages (the "mmap sweet spot")
- integrity & redundancy is handled outside this system, so long delays in durability are acceptable 1
This is a pretty reasonable workload, and I'm sure many people understand the type of data storage I'm hinting at. How can we adjust the vm sysctls to give us acceptable behavior?
Lets assume briefly we are writing in place. We know we do not want our hot files to be flushed. Since all pages are dirtied continuously, flushing hot files will result in a lot of wasteful writes to the same pages as they receive more updates. There are actually some implementation quirks that make this is especially bad, but even despite those, this is obviously inefficient.
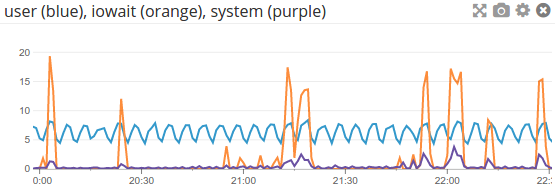
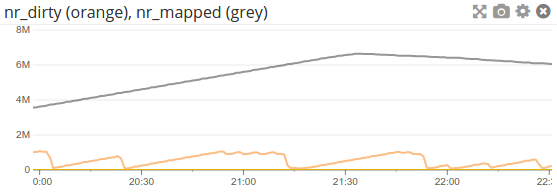
What we could try is to increase dirty_expire_centisecs to something > N-min. This way, as the flusher finally gets to these pages, they are no longer receiving writes. Unfortunately, this doesn't actually work in practice. Even setting the expire centisecs to 180000 (30 minutes) with 5-minute files still resulted in flush periods that reduced the number of dirty pages to almost nil, meaning that many inodes that hadn't yet existed for 30 minutes were getting flushed. Even worse, this will occasionally reach the hot file and continuously attempt to flush its dirty pages in vain until it eventually falls off the horizon and some other file takes over:
Stopping the Madness
For our workload, the available flush behavior is simply unusable. Instead of trying to get the memory flush threads to play nice, is there a way to get them to ignore our memory?
If you dig through the calcified strata of online linux documentation, you might discover that older versions of redhat (starting with 5.2) had a patch which added a sysctl flush_mmap_pages. This sysctl allowed you to globally shut off the flushing of mmapped pages to disk. This patch was sort of a stop-gap for a particular large customer, and is no longer maintained for new kernels. In any case we do want eventual persistence for our cold files, which may receive the odd occasional write.
Another option that looks promising is the mlock syscall:
mlock() locks pages in the address range [..] All pages that contain a part of the specified address range are guaranteed to be resident in RAM when the call returns successfully; the pages are guaranteed to stay in RAM until later unlocked.
Unfortunately, it doesn't actually say that these pages won't be flushed by the kernel flush threads, simply that the pager won't swap them out of memory. And in fact, they will be flushed; you simply can't reliably prevent file backed mmaps from being flushed.
Another related syscall is the madvise syscall:
The madvise() system call advises the kernel about how to handle paging input/output in the address range beginning at address addr and with size length bytes. [...] The kernel is free to ignore the advice.
The emphasis in the above is mine, but it should sufficiently warn you against relying on madvise. The only concrete action that the kernel seems to take from a call to madvise has to do with pre-loading pages you tell it you will use; it doesn't prevent anything from being flushed.
The Penny Drops
The only way to ensure that an mmapped region is not flushed to disk "prematurely" is to make it not backed by disk. You can do this by using the MAP_ANONYMOUS flag, or by mapping an fd which is backed by a shared memory object. These can be created via shm_open or a regular open on an shm filesystem like Linux's /dev/shm. The shm approach is particularly nice, since it behaves in many crucial ways like normal filesystems do:
- mapping a sparse file uses sparse memory, just like it uses sparse disk blocks
- standard operations like ftruncate + re-mmap work as they do on the fs
- shm objects persist until unlinked just like files, so you can restart a process using them
Rewinding a bit, it's worth examining the worth of this whole enterprise. mmap's unruliness is one of the prime reasons that a great deal of databases manage their disk persistence entirely manually, or if they use mmap, they assume they are either readonly or always dirty. It's why a great deal of storage engines that do usemmap have copy-on-write semantics; the API just does not allow enough control for update-in-place write patterns to be safe.
What would be brilliant, for Linux at least, would be a way of preventing the kernel from flushing mlocked pages. This would unfortunately be a dangerous change in semantics, as people expecting the current behavior will suddenly lose disk persistence, and mlock takes no flags to add this as an option. The mlock API and especially the very low default associated ulimits mean that it would probably have a bit of a niche use case, but the semantics aren't the worst fit.
There are, of course, non Linux options. The focus has been on linux thusfar because that's where I have the experience.
The FreeBSD version of mmap contains a MAP_NOSYNC flag which instructs the mm to only flush pages to disk "when necessary rather than gratuitously." The documentation goes on to say that this would usually be instigated by the pager, which suggests scenarios where the memory is probably more useful elsewhere.
I'd be interested in hearing some first hand accounts of how the FreeBSD (or other Unix kernels) differ in operation compared to Linux.
- That last one is key, because it is notoriously difficult to ensure any kind of consistency with a read/write mmapped file.